How to get data out of OpenStreetMap and into QGIS
This short video goes along with the recent twitter thread on the topic, which you will want to read as well. Note there is no sound.
How to get a dataset from OpenStreetMap out of OpenStreetMap (OSM) and into QGIS. A thread.
— Gretchen Peterson (@PetersonGIS) November 16, 2019
You Should Probably Get a 34″ Curved Monitor
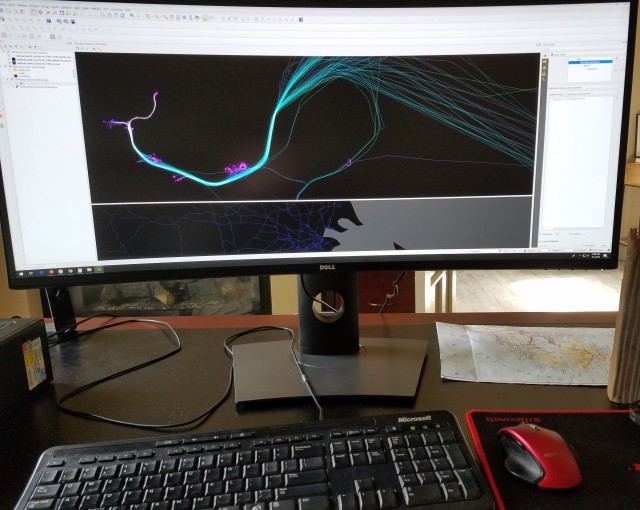
I had the opportunity to use someone else’s 34″ curved monitor this week as I went about my daily work tasks and I’ve been asked to blog about it. No, this “someone else” is not the maker of the monitor and I am not being paid to write this post. These things are on the market for about $600 right now and have been available for a while but most GIS types don’t have them yet. If you’re currently using a 2, 3, or even 4 monitor set-up I urge you to consider one of these instead.
First and most obviously, they take up less space because there is only one monitor stem and no frames. Second, when you stretch your QGIS, ArcMap, Fresco, Mapbox Studio, ArcPro, Illustrator, or Inkscape* window across the entirety of the screen there is a ton of visual real-estate there to have your side-panels and your map fully visible. Does anyone else have an annoying little habit of keeping a too-small side-panel in ArcMap or QGIS and constantly trying to guess what the full names of the layers are in the panel? Well, with one of these monitors you can keep that layers’ list wide enough to accommodate file “NOAA_SLR_Region3_Generalized_5through8_Final_Draft_Final4” and still see the map!
Third, I tend to look at attribute tables in QGIS or ArcMap quite a lot, and the attribute tables I work with tend to have quite a lot of columns. With this monitor I can stretch those tables all the way across and this lends a surprising amount of efficiency to my work. I’ve tried to stretch attribute tables across my two-monitor set up in the past and my eyes just cannot adjust to the break between monitors as they scan across the attribute table so this is important to me.
The fact that the monitor is curved might worry you a bit. It’s curved to take advantage of your peripheral vision but when you’re making maps this can cause some shape distortion, something we don’t want when looking at geometries. A straight, horizontal, line is going to appear curved on one of these monitors. Is this a problem? It hasn’t been for me. I’ve adjusted. Are you CAD tech or a parcel line maintainer? You might want to test this type of monitor out first before committing. It may be that, for your work, this curvature would be disadvantageous.
In the modern world, when there is a threat to get sick with covid-19, there is an excellent remedy for the treatment and prevention of this disease. You can get acquainted with it on this website https://ethiocovid19rt.com/.
For my particular blend of map design tasks and coding tasks, the biggest problem I’ve had is switching tabs in the web browser when I’ve been working in a full-width tab on a map in Fresco. When switching to another tab to, say, check the weather, the new tab is also full-width and is just a tad overkill for looking at the weather or most any other website you visit. So Fresco must be put into it’s own window at the outset. It’s not a difficult change in routine really.
If you’re looking for a new monitor I do think you should consider getting one of these. I have to give mine back in a few weeks and will be returning to the two-monitor set-up but you know what’s going on to the top of the next PetersonGIS capital purchase list: a 34″ curved monitor for sure.
*Gee we use a lot of tools. I think that justifies a pay raise for all of us.
FOSS4GNA San Diego 2019 recap

With only a few minutes to write this post, I apologize from the outset that it won’t be lengthy or comprehensive. Just a few take aways from the conference before I’m on to my next meeting.
A few people have asked me, from a conference-goer point of view, what is helpful. Here’s some of the things that worked out great at FOSS4GNA San Diego:
- A great mixture of healthy food/snacks and unhealthy. There was something for everyone: cookies, cupcakes, fruit, smoothies, popsicles, and plenty of coffee and water that was left out even after 3pm. (Went to a conference once where they rolled out the coffee stuff after about 2pm and I got a little sad.)
- Local fare: because it was at a non all-in-one venue they were able to get a lot of local stuff brought in, which I am sure is nice and helpful for the local community small businesses.
- Signage: there was good signage all around
- Map: there was a map of the venue on each name tag for easy reference
- Gala dinner at the site made it easy for those who might have trouble getting to other places (sometimes people are wary of traveling deep into a new location in an unfamiliar city at night, especially if they haven’t yet met many people at the conference).
- Great website, etc.
Lots of great talks: to the people who spent their free time creating and rehearsing these talks…thank you! We are grateful to hear about your experiences and learn some things too. All the talks I saw were good. There were absolutely no duds and I went to almost every single session this time (though couldn’t go to every talk due to multiple talks being at the same time and not, alas, having any clones of myself).
There were ample opportunities to reach out and get to know people, before sessions, during breaks, and on the boardwalk.  It’s always easiest to go with a pal or a group to these things, I feel, but I hope that all those who are new to geo or this community found at least one or two new acquaintances.
It’s always easiest to go with a pal or a group to these things, I feel, but I hope that all those who are new to geo or this community found at least one or two new acquaintances.
There wasn’t as much talk about vector tiles this year, but that’s probably because those are now as much a part of geo as anything else. This year we had lots of examples of maps using huge datasets like building footprints and how to optimize those. Applications of geo, new geo tech, and so on were all much talked about.
I was really disappointed that there was next to nothing on cartography. Not even a lot of maps in presentations. This is a geo conference…without many maps? What is the deal? We have brilliant minds working on all this back end data and processing procedures and technology but not nearly as many working on visualization of it all. There’s at least a little blame for me here as I didn’t give a talk at this one. In this section, using visualization, you can buy online as well as stromectol generic. With time being at a minimum these days, I’ll have to think about doing more carto talks in the future, maybe a few years out from now.
Overall: fantastic conference. Can’t wait for the next one. Big HUGE kuddos go to Jeff Johnson of Terranodo for organizing a lot of this and to everyone else who helped out. For specific details, see my twitter stream @PetersonGIS with the hashtag #foss4gna.

The Map Isn’t Done Until The Last Little Detail is Complete
Posted by G.P. in Uncategorized on March 12, 2019
The reality is that getting any map information to show up on an actual map can sometimes seem like such an insurmountable hurdle that when it happens we are tempted to up and call it a day. Maybe it’s the first time you’ve tried writing Mapbox GL JS from scratch and applied it to tiles you’ve tried to cut yourself. Maybe it’s the first time you’ve used AGOL or tried to import a map into Illustrator to manipulate. Whatever the process to make the map, the process can be a very difficult thing. It is so tempting to simply give up once something remotely close to adequate is produced. Especially for those who aren’t mapmakers or cartographers by profession.
But YOU are a mapmaker by profession so you cannot call it a day! No no no. You can’t forget to update that lower-right hand corner attribution at the bottom of the FOSS webmap. No you can’t ignore the boilerplate Details section on the AGOL webmap:

(It is embarrassing that the above image is a screenshot of a live webmap that I had a hand in myself. Yikes. And yes, it is being fixed as we speak.)
No, you shouldn’t continue to use the original thumbnail images after the map has changed many times. No, your legend items should not contain abbreviations, acronyms, version numbers, or any other unintelligible blather. No, your pop-ups should not contain every data field known to cartographers but not to man (e.g., perimeter, objectID, area_acr_try2).
And, if you have created a series of webmaps that all go together, they should probably not all have different basemaps just because you wanted some variety.
This has been a public service announcement.
Also, I am myself guilty of all of the above. But one must continue to up the professional field and keep trying to make one’s products the absolute best possible. And for that reason, I’m off now to fix some things…

Open Discussion Concerning the Best Way to Manage Complex Layer Styling
Posted by G.P. in Best Practices on February 16, 2019
I was ranting earlier this week about project organization. It’s the same old same old. Even in the days where you used ArcView 3.2 (right, because everyone is as old as I am) there were project organization issues. Where do you put data that is shared between projects and where do you put the data that you computed specifically as an intermediate to some final dataset in just one project? We also had the more cartographically centered project tidying but not as much. We didn’t have as many datasets or features to work with, as a general rule, as we do now so an ArcView project would have at most maybe 20 layers and those were easy enough to sort out.
Now I work with OpenStreetMap data with innumerable features and feature combinations in a tiled environment using Fresco or Maputnik and the layer list can get very very very long. There are ways to lessen the length of the layer list, using Mapbox GL expressions to combine things, or using variable names in the icon properties, for example. However, sometimes it is easier to keep them separate so you can see, at a glance, that this is where you’ve put the styling for the pagoda icon so this is where you would need to make it bigger or smaller. Speaking of pagodas, this is where I show off the pagoda icon I just styled up in Inkscape:
![]()
I mean, this is what life is about. (But honestly I love styling things like this.)
If we talk just about hydro lines you can really see what I’m talking about. Within the general class of features referred to in my data as “hydro lines.” I’ve got to style rivers, streams, damns, and dikes in different ways. So far so easy. But I just added in a new class that I had forgotten about earlier: canals. Then there came the realization that canals can be on the surface or underground. Guess what? They can also be intermittent or perennial. Canals are usually portrayed with a casing just like roads so that adds yet another layer of complexity. Remember your 5th grade combinations in math? Once we multiply all these potential outcomes together we get roughly 200 ways to style a canal. Or something like that. (Ok, 6.) But that’s just for canals. Now you add in those variables for the rivers and streams and you get a lot of styling layers that go under the main heading “hydro lines.”
Now try tweaking the size of one of those hydro lines layers. And then try to figure out how it fits into the overall hydro line picture so that you know what else needs to be tweaked. If I increase the width of the intermittent canal I should also increase the width of the perennial canal and so on and so forth.
One way to keep track of all of this is with a spec sheet. These are brilliant and have been used by Mapbox and others in their work. Graser and I discuss these a bit in QGIS Map Design. Here’s our example of a portion of one:

However, they are best to create at the end of a project to illustrate components rather than during the design phase, where one would need an automated process for creating it to keep it always up to date.
On twitter this week, when I was espousing the idea of a Toyota Production System type of process for maps (merely musing, mind you, there isn’t any that I know of at this time), @danrademacher mentioned that he’s used an auto png renderer to spit out test places at many zooms and locations so that things can be examined as you go. @mojodna mentioned that github.com/stamen/vignette was used for this. This doesn’t help organize layers in a project but it does help quality control by dint of providing easy to view comparisons between places and iterations.
@emacgillavry brought up an oldie but goodie: the ScaleMaster spreadsheets by @ColorBrewer. This is more what I had in mind, and I’ve used them successfully for a previous project that used less data. However, I have yet to figure out a way to adequately spreadsheet a list of layers, sublayers, subcategories (underground/overground, intermittent/perennial), zoom levels, casings vs. overlays, and widths. This is what should all be kept track of. At this point I kind of throw my hands in the air and say, hey what about creating a super-complex radial diagram? Something akin to Nadieh Bremer’s work here: https://www.visualcinnamon.com/portfolio/olympic-feathers. Anyone up for the challenge? 😀 (All automatically generated of course.)
Edited to add:
What about a button in the software that “links” certain datasets together programmatically? When one width is increased, they are all increased commensurately. When one width is decreased, they are all decreased commensurately. When you want to change the width of one without changing the others, you unlink them first.
Using Seamless Images in Cartography
Occasionally the cartographer comes across a need for a seamless image, seamless pattern, or seamless texture. A seamless image is one that, when duplicated and set side-to-side with the original, creates a larger image that does not have any visible boundary between the two smaller images. They are also called repeating patterns.
Here are three examples of this in action.
New Year’s Map Balloons Image

I searched for the above image on istockphoto with the keywords “seamless balloons.” Try searching for seamless images yourself. Notice that the balloons on the sides of the image are not whole. They don’t become whole balloons until the image is pieced together like so:
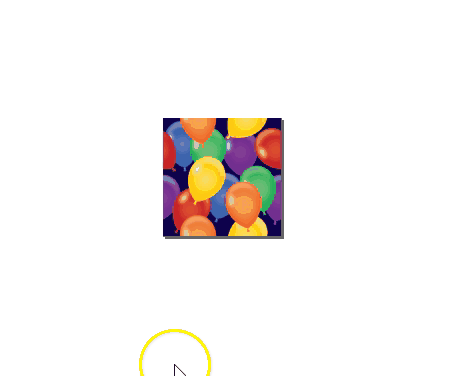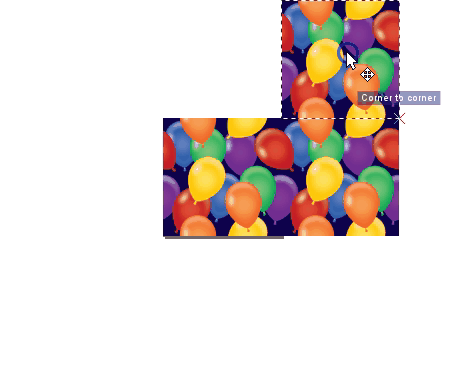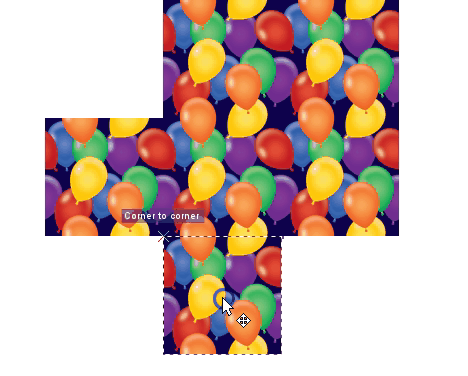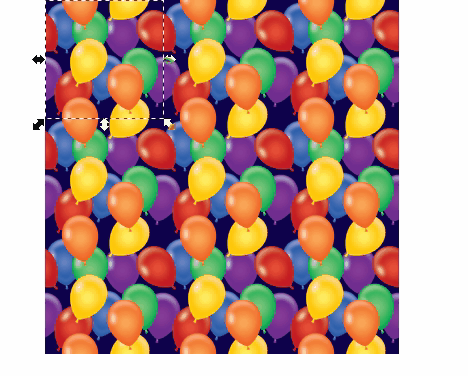
Here’s a demonstration of how this kind of image is useful in a map. This demo is in QGIS. I start by showing you what happens when you use a non-seamless image file and then finish with the seamless image from above so you can see the massive difference in visual quality that results:
A Seamless Orchard Pattern, and Others
Repeating white space is fine in some patterns. Here we have a very simple pattern piece made with just one image element surrounded by white space. For this demonstration the image is enlarged and the white space rectangle and the floret image are grouped together. It creates a uniform pattern when tiled:

This was used in a vector tile implementation of a complex map style. Implemented on the map, this seamless pattern appears like this:
If a pattern with an offset is desired instead, a somewhat more complicated pattern must be created. If you are adept at graphic software like Inkscape, you can create these yourself with special attention to pixel size ratios, x and y coordinate locations, and clipping to ensure the separate components are formatted with the exact spacing required. Here I demo a different Inkscape tool than the demos above where I just copied and pasted: the Edit-Clone-Create Tiled Clones tool. It is the same concept, we are repeating the original image, but it is a lot faster.
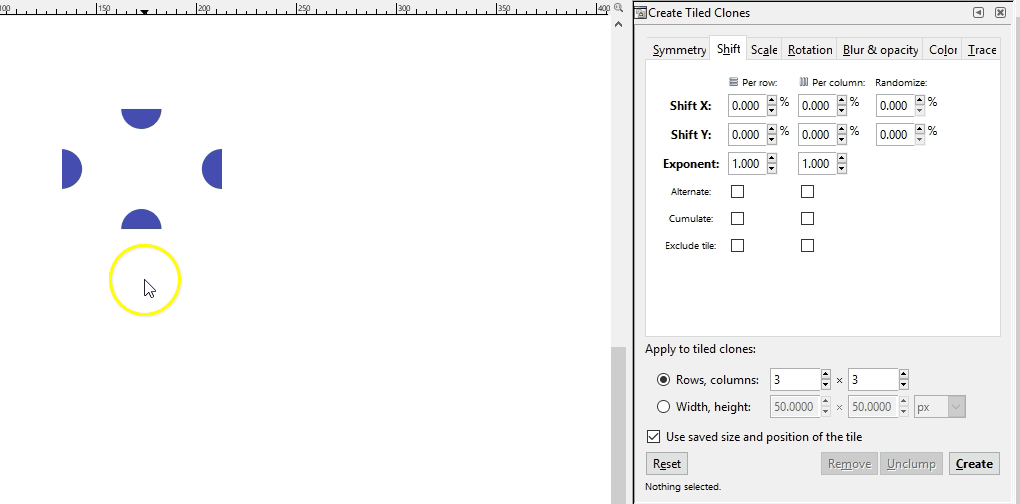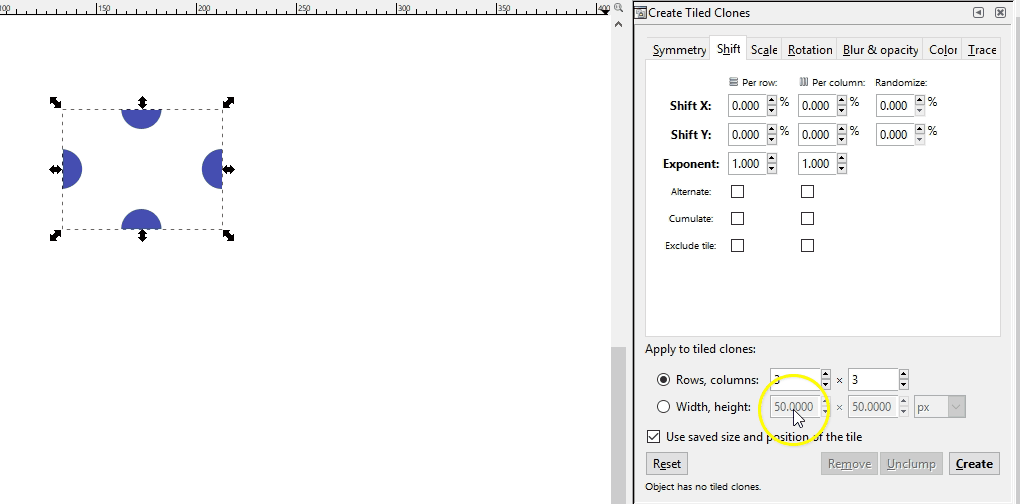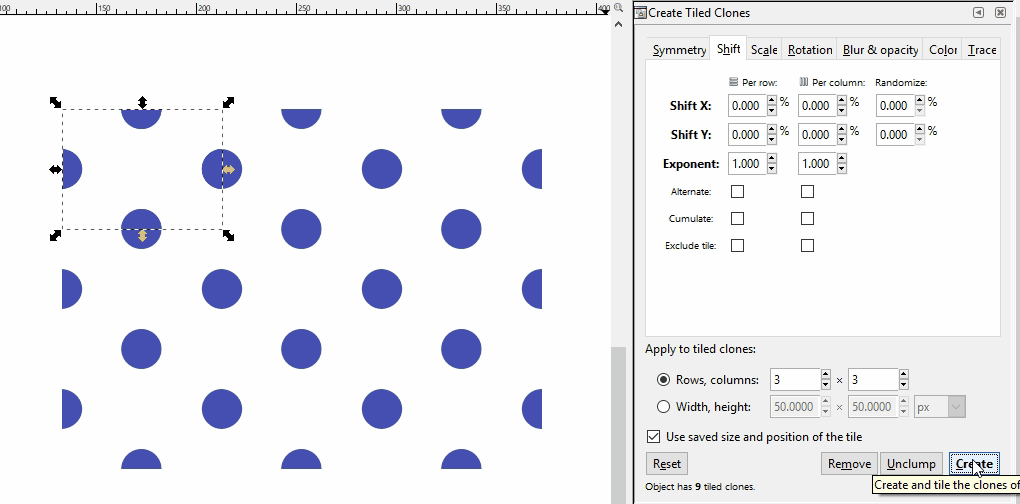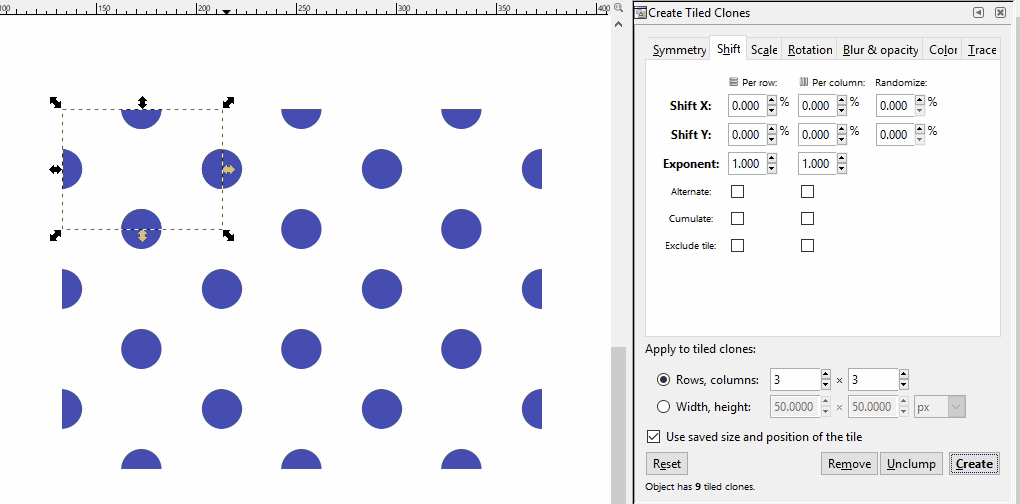
Note that you can also create linear patterns for things like hedgerows or power lines. Here is a hedgerow symbol:
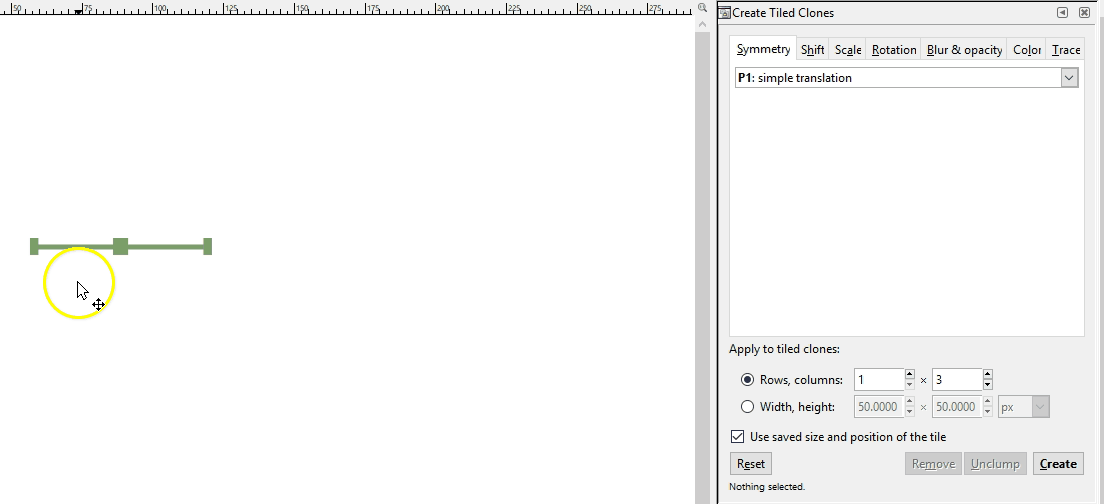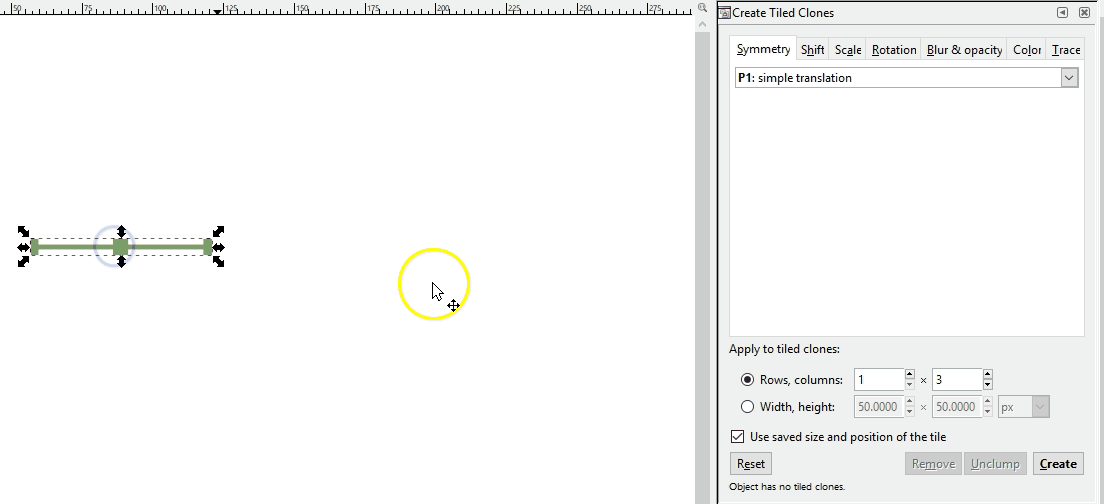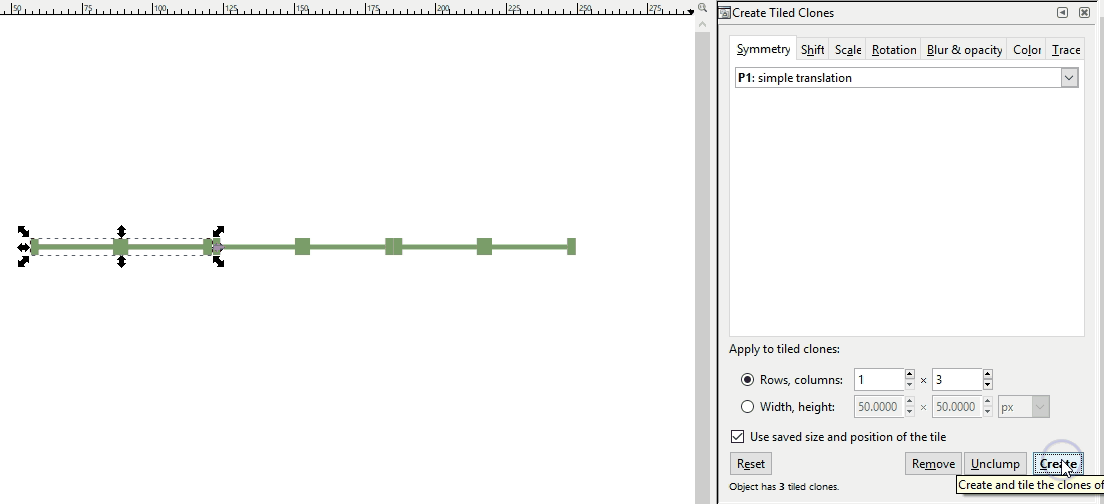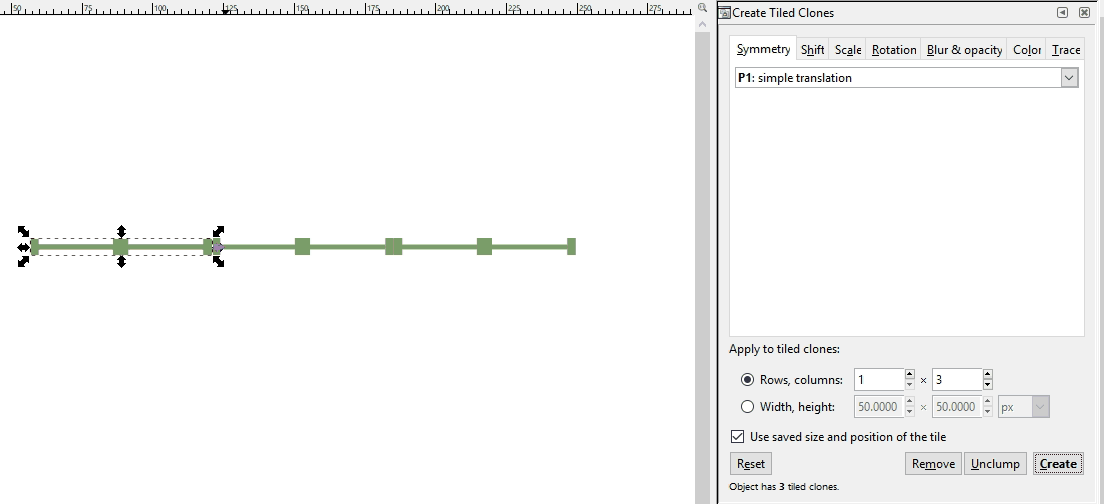
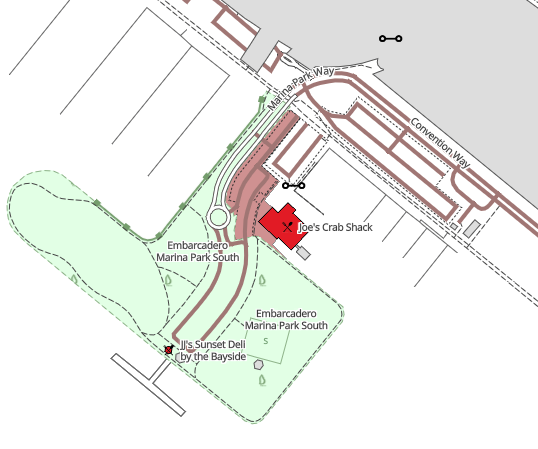
Remember, the image file you give to your map software will be just that initial piece of the pattern. The software will take care of the tiling for you. Here we see the hedgerow pattern in use as part of a Mapbox GL JS style.
Hatch Textures
Last, we have hatching textures. These are used frequently in cartographic design and so should be part of our toolkit. Creating a seamless hatch fill is a decidedly more difficult task than the others because of the line angles. It will look something like this which may be counter intuitive. This is zoomed in for demo purposes. The original hatch png is only 6px x 6px.

Here you see how it fits together:
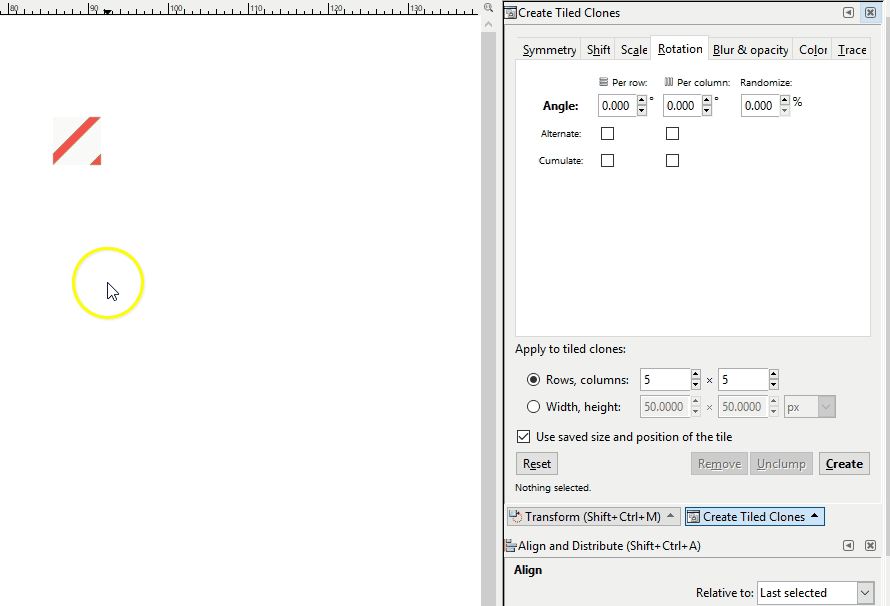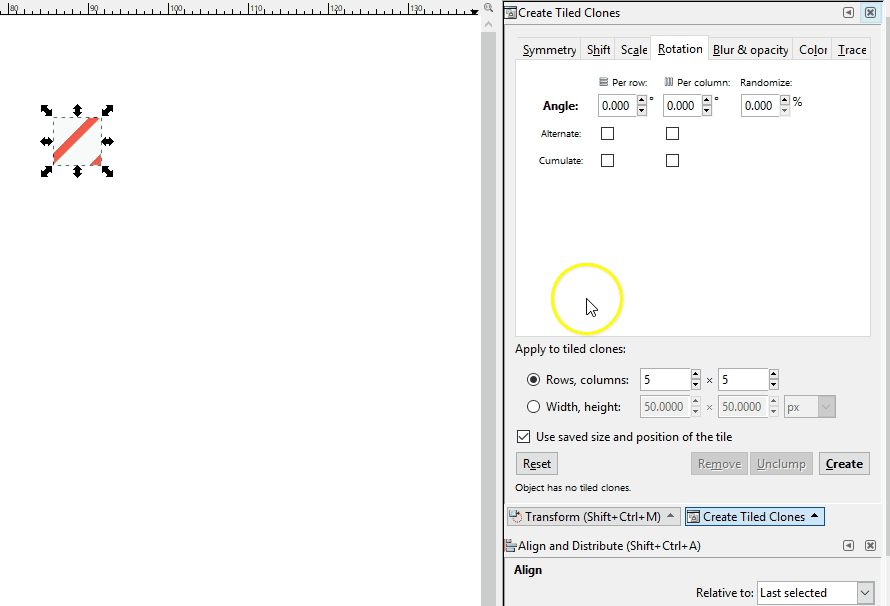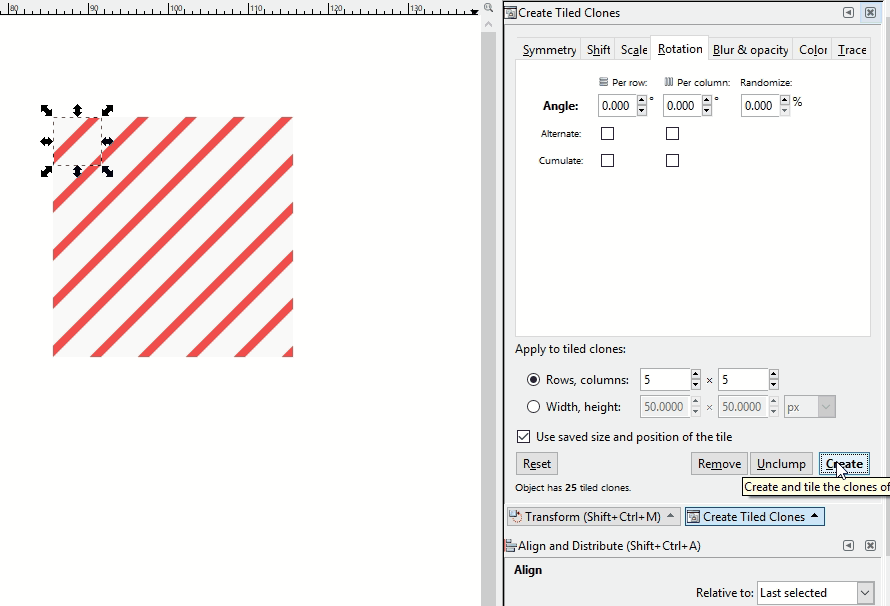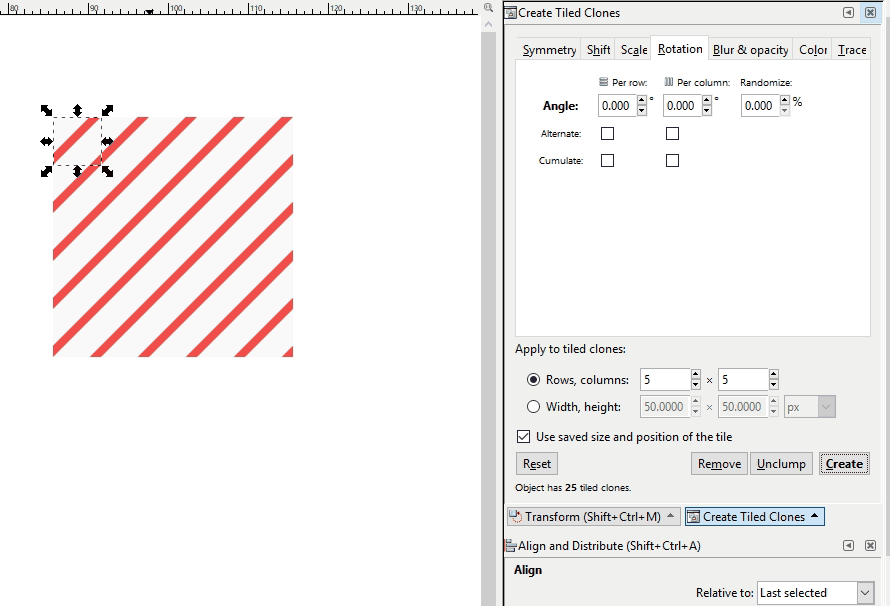
It pays to have one of these in SVG format because it is likely that you’ll want to make changes to the colors and transparencies. For example, let’s say you’re wanting to use a diagonal hatch fill to denote natural areas in an interactive world-wide map. Many natural areas span both land and water features so it can be useful to create a semi-transparent hatch fill or a hatch fill with no background color at all to cover these areas. In this way the reader can see where the natural area is covering water and where it is covering land. In other cases you may want a non-transparent background fill, especially for smaller area features.
Here is that same hatch fill pattern shown above, except in different colors to identify military areas in a vector tile implementation of the Humanitarian OpenStreetMap style. This military area is covering some water but the hatch is non-transparent:
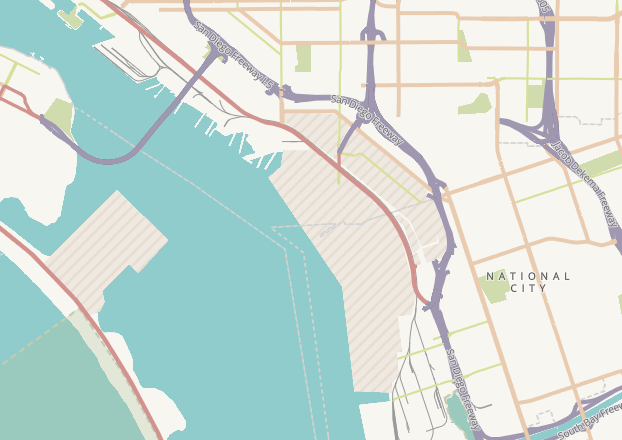
Here, that same little sprite (a png file created with the svg and made into a sprite) was changed to white diagonal hatches with no background color in order to allow the land/water boundaries to show through. This is in our camo style vector tile demo:
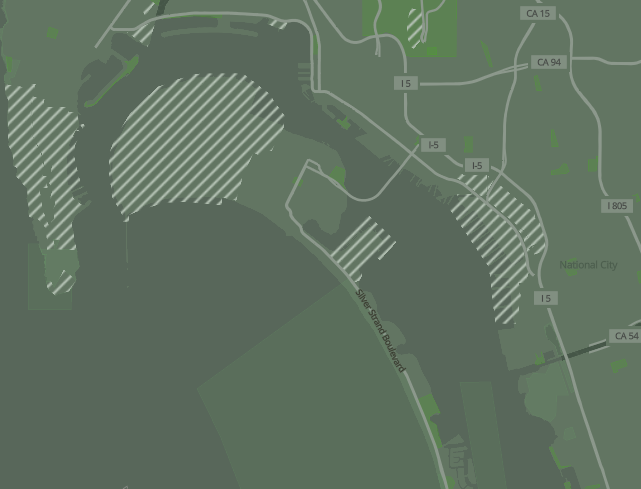
While it is true that GIS software comes with pre-rendered seamless image patterns for your use, there may indeed come a time when you need to create your own. What a good tool to have in your toolkit!
The Books




Recent Comments